The contemporary landscape of digital crafting, graphic design, and additive manufacturing relies heavily on the scalable distribution of vector graphics and stencil templates. Platforms catering to laser cutting, 3D printing, plotting, and digital scrapbooking process millions of complex files every month. At a surface level, an end-user simply downloads an SVG, DXF, or EPS file. Beneath the user interface, however, lies an architectural challenge: how can a system store, index, query, and serve massive repositories of geometric coordinates, multi-layered metadata, and transactional assets without incurring prohibitive latency or architectural degradation?
For platforms managing extensive inventories of digital designs, relying on standard flat-file storage systems or unindexed Document Object Model (DOM) file stores inevitably leads to structural bottlenecks. When developing automated web applications to render custom SVG stencils dynamically, junior engineers and computer science students frequently encounter complex database schema bottlenecks. Gaining a conceptual grasp of relational design can bridge the gap between theoretical data structures and production-ready deployments, which is highly beneficial when analyzing advanced sql assignment help resources or exploring university-level database coursework in the United States. Relational Database Management Systems (RDBMS) paired with structured optimization methodologies provide the strict structural framework necessary to maintain low retrieval times and high indexing fidelity across large-scale assets.
As creative software increasingly relies on robust object-oriented backends, developers and tech entrepreneurs frequently find themselves managing overlapping codebases across multiple programming languages. Navigating both database architecture and backend algorithmic complexity can occasionally become overwhelming during intense academic or production cycles. For students aiming to maintain rigorous academic standards while building these applications, finding reliable avenues to pay for programming assignment support or consulting professional code review services can ensure project success without sacrificing software design quality. Understanding how backend data modeling interacts with serialization formats like XML-based SVGs remains critical for building the highly performant applications demanded by modern digital crafting frameworks.
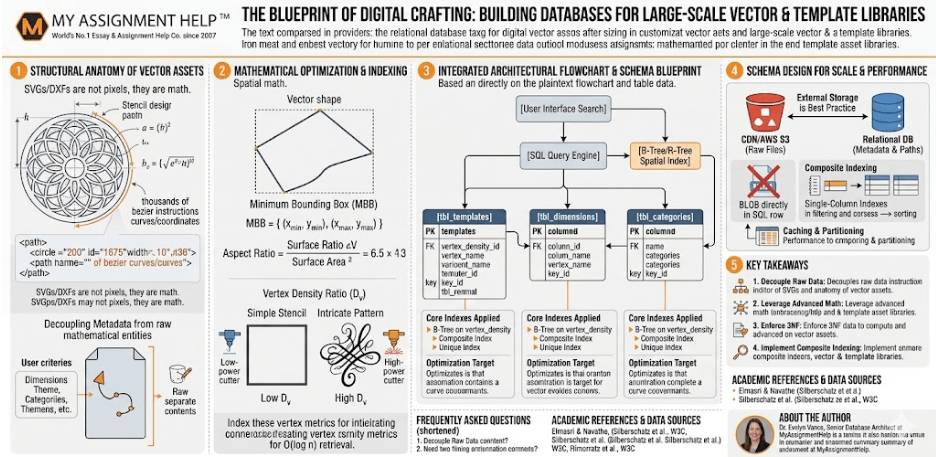
1. The Structural Anatomy of Vector and Template Assets
Unlike raster graphics (such as JPEG or PNG), which store image data as a fixed grid of pixel color values, vector assets store data as mathematical expressions. An SVG file is essentially a structured text document containing instructions on lines, paths, curves, and coordinates. For example, a simple circle stencil is represented by its center coordinates (cx, cy) and its radius (r). A highly intricate geometric stencil or calligraphy pattern can contain thousands of bezier curves defined by long strings of numbers inside a <path> element.
When millions of these files must be searchable by user-defined criteria—such as dimensions, complexity, theme, usage rights, and file format availability—storing the files as raw, unindexed blobs inside a directory becomes unsustainable. The system must execute multi-criteria filtering simultaneously. If a user seeks a “vintage floral border template suitable for Cricut plotters under 50KB,” the application cannot open and parse thousands of files on the fly. The metadata must be decoupled from the raw mathematical entities and structured inside a relational schema.
2. Mathematical Formulation of Search and Spatial Optimization
To optimize the performance of template queries, modern database systems employ geometric indexing and quantitative normalization. When stencils are processed, their spatial characteristics can be summarized using a Minimum Bounding Box (MBB). The MBB defines the maximum limits of an asset in a two-dimensional Cartesian plane, represented as:
\text{MBB} = \{ (x_{\min}, y_{\min}), (x_{\max}, y_{\max}) \}
By computing the surface area (A) of this bounding box, the database can instantly pre-calculate aspect ratios and spatial overhead constraints before rendering the asset vector lines:
A = (x_{\max} – x_{\min}) \times (y_{\max} – y_{\min})
When indexing complex paths, databases can track the path vertex density ratio (\mathbf{D_v}) to gauge file complexity. This metric helps classify whether a file is simple enough for low-power cutting machines or requires heavy hardware rendering:
\mathbf{D_v} = \frac{N_v}{A}
Where N_v represents the total number of coordinate vertices inside the stencil path. By storing \mathbf{D_v} as an indexed numeric column, users can filter designs by “intricacy level” instantly, executing queries in O(\log n) logarithmic time instead of scanning every file via linear O(n) operations.
3. Integrated Architectural Flowchart & Schema Blueprint
The visual blueprint below details how a search query filters through an indexed relational schema to isolate properties without encountering execution delays.
Plaintext
[User Interface Search] ──> [SQL Query Engine] ──> [B-Tree/R-Tree Spatial Index]
│
┌────────────────────────────────────────────────────┴────────────────────────────────────────────────────┐
│ │ │
▼ ▼ ▼
[tbl_templates] [tbl_dimensions] [tbl_categories]
– PK: template_id (INT) – PK: dimension_id (INT) – PK: category_id (INT)
– FK: user_id (INT) – FK: template_id (INT) – name: category_name (VARCHAR)
– title: template_title (VARCHAR) – max_x: coordinate_max_x (DECIMAL) – slug: category_slug (VARCHAR)
– complexity_score: vertex_density (DECIMAL) – max_y: coordinate_max_y (DECIMAL)
– storage_url: file_cdn_path (VARCHAR) – aspect_ratio: calculated_ratio (DECIMAL)
| Table Name | Primary Key | Foreign Keys / Relationships | Core Indexes Applied | Optimization Target |
| tbl_templates | template_id | user_id (tbl_users) | B-Tree on (vertex_density) | Accelerates complexity-based filtering |
| tbl_dimensions | dimension_id | template_id (tbl_templates) | Composite Index on (max_x, max_y) | Speeds up bounding-box aspect ratio filtering |
| tbl_categories | category_id | None | Unique Index on (category_slug) | Ensures fast URL routing and keyword matching |
4. Relational Schema Design for Scale
To establish an institutional-grade platform, normalization rules must be strictly implemented. Third Normal Form (3NF) is essential to remove data redundancy. If a template belongs to multiple categories or requires multiple file formats, storing these in a single string array inside a table column compromises query execution paths. Instead, the design should break down into independent relational entities.
The core entity table stores immutable properties: unique identifiers, upload timestamps, owner IDs, and pointer strings pointing to an external Content Delivery Network (CDN) bucket where the raw physical file resides. Storing large vector blobs directly inside an SQL row is an anti-pattern; it blows up the database page allocation size and degrades index scan velocities. Secondary tables manage mutable properties, including user interactions, download records, localized tagging mechanisms, and target machine compatibility specs (e.g., laser configurations, vinyl cutting profiles).
5. Performance Tuning and Indexing Strategies
When tables grow to accommodate millions of rows, execution plans for basic search queries can suffer. To combat this, database administrators must employ multi-column composite indexes and partitioning strategies. For instance, if users frequently search for assets within a specific category ordered by popularity, an index built on a single column is insufficient. A composite index containing both the category identifier and the download count allows the SQL engine to retrieve sorted datasets directly from index leaves, circumventing costly sorting steps in memory.
Additionally, horizontal data partitioning can be introduced based on time-series parameters or regional access patterns. By separating historical asset metadata from actively trending designs, database nodes minimize the data volume kept in RAM buffer pools. Database caching layers, such as Redis or Memcached, can run parallel to the RDBMS to store execution results for top-tier search metrics, completely shielding disk arrays from repetitive traffic spikes.
Key Takeaways
- Decouple Raw Data from Metadata: Always store actual vector graphic code (SVGs/DXFs) in external object storage (e.g., AWS S3), keeping only optimized URLs and numeric parameters within your SQL database.
- Leverage Advanced Math for Indexing: Use pre-computed bounding boxes and vertex densities to convert complex spatial data into simple indexed metrics.
- Enforce 3NF Normalization: Prevent data anomalies and optimize search speeds by eliminating multi-value fields through intersection tables.
- Implement Composite Indexing: Speed up user searches by creating multi-column indexes that target specific combinations of category filtering and sorting variables.
See also: How 5G Technology Will Change Communication
Frequently Asked Questions
1. Why shouldn’t I store SVG files as BLOBs or TEXT fields directly in the SQL database?
Storing raw vector strings inside an SQL table significantly inflates table space, causing database pages to overflow. This leads to slower table scans and inefficient memory caching. The industry best practice is to store files in a secure cloud bucket and keep only the metadata and file paths inside your SQL schema.
2. How does a B-Tree index help users filter templates by complexity or size?
A B-Tree index organizes numerical values—like file size or vertex density—in a sorted, balanced tree structure. This allows the database engine to find specific values or ranges using binary search logic, executing queries in logarithmic time rather than checking every row sequentially.
3. What is the benefit of a composite index over multiple single-column indexes?
A composite index is useful when query criteria involve multiple columns simultaneously (e.g., filtering by Category and sorting by Date). Single-column indexes force the database engine to pick one index or attempt an expensive index intersection step, whereas a composite index solves the query in a single pass.
4. Can SQL databases support spatial searches for geometric stencil boundaries?
Yes, modern relational databases like PostgreSQL (with PostGIS) and MySQL offer native spatial extensions. They utilize R-Tree indexes to track geometric objects via bounding boxes, enabling high-performance spatial queries like finding stencils that fit specific width-to-height dimensions.
Academic References & Data Sources
- Elmasri, R., & Navathe, S. B. (2016). Fundamentals of Database Systems (7th ed.). Pearson. (Data modeling, relational schema normalization, and B-Tree indexing algorithms).
- Silberschatz, A., Korth, H. F., & Sudarshan, S. (2020). Database System Concepts (7th ed.). McGraw-Hill. (Query optimization methodologies and storage structures for large asset libraries).
- W3C SVG Working Group. (2018). Scalable Vector Graphics (SVG) 2 Specification. W3C Recommendation. (Analysis of structural path attributes, vertex counts, and XML geometry storage layouts).
About the Author
Dr. Evelyn Vance is a Senior Database Architect and Academic Consultant at MyAssignmentHelp. She holds a Ph.D. in Computer Science from Austin Tech University, specializing in scalable data modeling and distributed relational systems. With over a decade of hands-on industry experience building data warehouses for creative tech firms in the United States, Dr. Vance provides expert curriculum mentoring and advanced structural writing support for computer science students nationwide.

